
Posted
Hi,
Is there any way to have deterministic control over auto-splitting after an import?
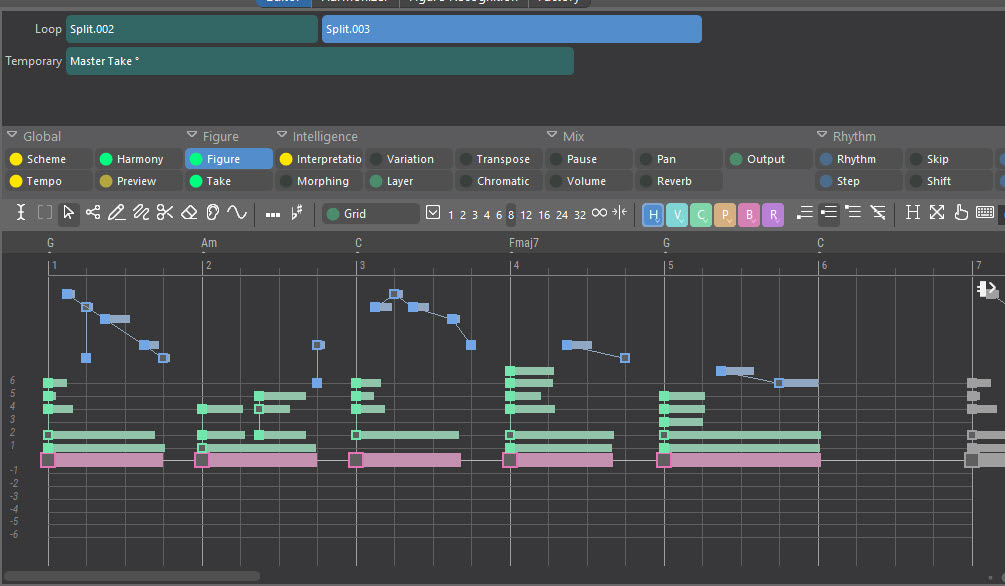
For example, consider this 8-bar take resulting from a MIDI file import:

What I want to do is to split this into 8 1-bar phrases (a pretty obvious choice IMO, if you look at the data).
-
the Auto-Split menu does not offer a 1m choice (why not?)

2. Even if I select 2m, hoping to get 4 clean 2m phrases, that is not what happens.
What I actually get is a 4m phrase, with silence at the end:

and a 5m phrase with silence at the end:
None of this is useful (or as intended), yet what I've asked for seems like it should be super-simple to accomplish.
Is there something more I need to know about this situation?
Is there room for program enhancement here?

Sat, 2023-12-02 - 20:54 Permalink
Splitting has room for improvement. The next build will already include some.
Splitting however is not about slicing a phrase into equally long parts.
It is content-sensitive, i.e. it's about guessing which spans of a long imported track (often unquantized raw takes) make good reusable phrases. The length is merely a preference to assess which results are best. That's also why there is no 1m preference.
I understand that slicing can be useful if data is fully quantized (drum loops, etc). That's pretty easy to add. The way to do this now is to select a span and do Command/CTRL-E.
Sat, 2023-12-02 - 21:15 Permalink
Thanks.
I understand that splitting, currently, is one of the "intelligent" operations of Synfire.
I feel the need to comment that sometimes "just doing what is asked" is the most intelligent thing that can happen when that is what is desired.
So, in the best-of-both-worlds spirit, I very much hope that both literal splitting-as-specified and 1m splitting specifically can become part of Synfire in the future.
Sat, 2023-12-02 - 21:19 Permalink
Thanks also for the reference to spanning and Ctrl-E.
In this case, I did know that but it's a good point to make in case not every reader of the thread does.
I'm confident you understand that spanning and Ctrl-E eight times for the given example, then again every time for every similar file that might be desirable to import is exactly what we users are looking to auto-split to enable us to avoid.
Sat, 2023-12-02 - 21:25 Permalink
We just need distinct names for that. Splitting vs. Slicing vs. Partitioning vs. Extracting ...
Implementing sophisticated algorithms is easy. What's really hard is all the product bureaucracy - how to name things, where to place them, how to organize them, where to store them, how to make them forward-compatible with respect to future development, all that.

Sun, 2023-12-03 - 09:04 Permalink
just in case the the nice alignments of the source data don't start replicating from the very beginning.
That's where the mess begins. What is "nice alignment" and what does it mean for different types of instruments? Drums and rhythmic keyboards are simple. Other instruments are often overlapping measure bounds and have long clumps of activity that are difficult to divide into useful phrases. Reverse-engineering a MIDI track into "source" phrases is not trivial.
Auto splitting was designed for unattended operation during batch import. It's not perfect. The next update it will be much improved using a more intelligent clustering.
For more control you must do the extraction of interesting spans from the master take with CTRL-E after a static import. After all it's a creative decision what kind of phrases you are looking for. Only 20% of a MIDI file track are useful for that purpose anyway.
That said, a function that splits by 1m or 2m will be useful. Everything above 2m requires manual review anyway.
Sun, 2023-12-03 - 14:10 Permalink
That said, a function that splits by 1m or 2m will be useful.
Agreed!
Everything above 2m requires manual review anyway.
But I would quibble with this. Some source material may be quite regular, and 3m or 4m ingestion of chunks could be desirable.
Here is just one possibility - suppose I have MIDI files which I have created by recording in DAW, with a one bar count-in, with the specific intention of improvising 4m phrases, albeit with my less-than-professional-level of keyboard playing. I improvise for 10 minutes. Now I want to ingest into Synfire. For alignment I need to throw out the count-in, and the subsequently I want 4m phrases, and nothing else, because that is the nature of the source material. I don't want to go thru that source chunk by chunk to audition it and then Ctrl-E my favorites. Just the opposite. I want to ingest all the 4m chunks into Synfire and audition them from the phrase pool, marking only favorites. Then I trim the pool in a single operation to leave only the favorites. This is the fastest workflow by far for this scenario. And it is technically simple (if I may say so). Thus, I look to Synfire to enable me here, not disable me. Fair, I think!
Other use cases can be imagined also. IMO it shouldn't be necessary to list, rank, and value them in order to arrive at go/no-go justification for flexible split/chop. The flexibility is it's own argument. The users will do with it what they will, and that may be wildly different from anything anticipated in advance.