
Posted
Hi,
I have imported a simple .mid file (attached), using these settings:
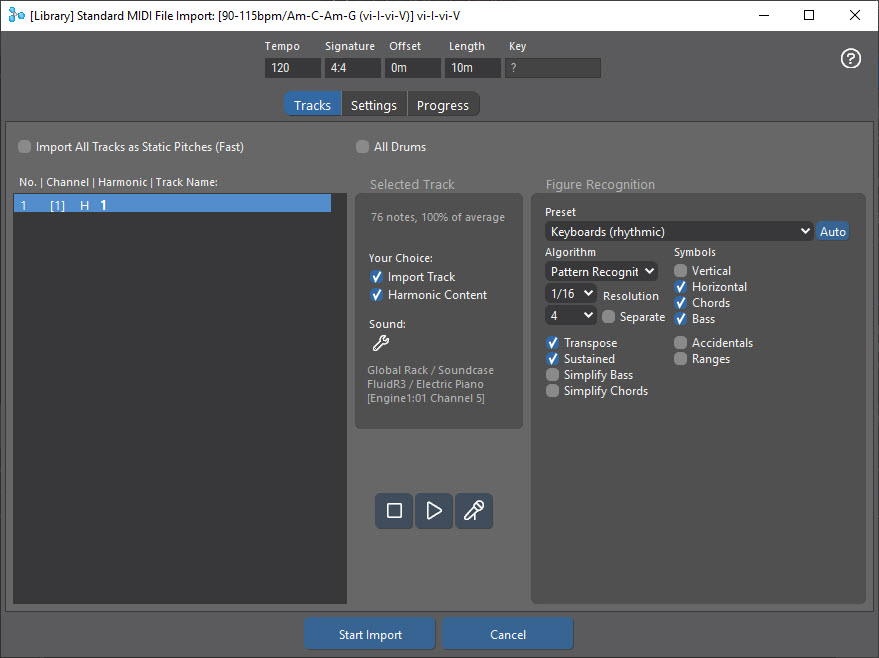
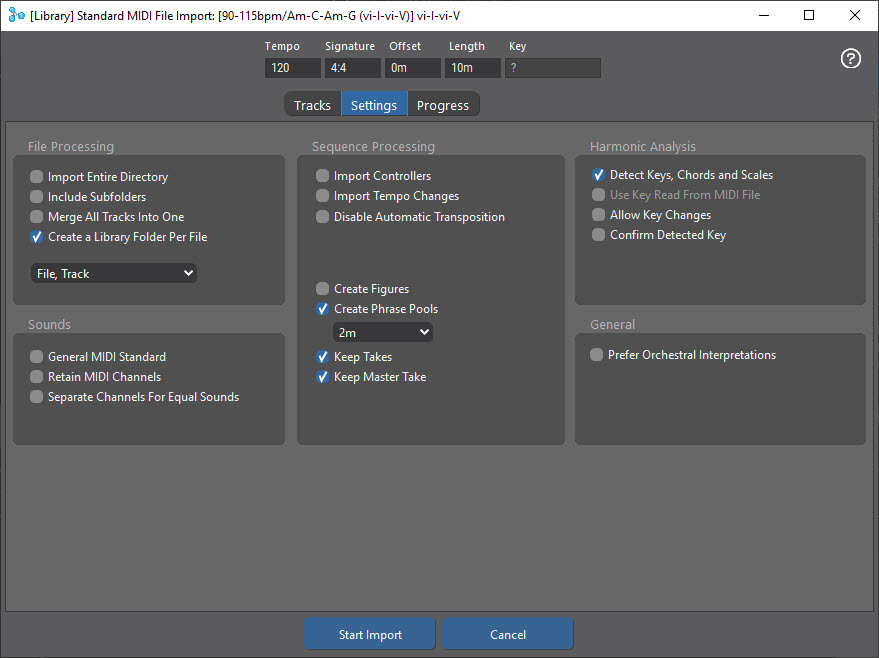
The results looks like this:
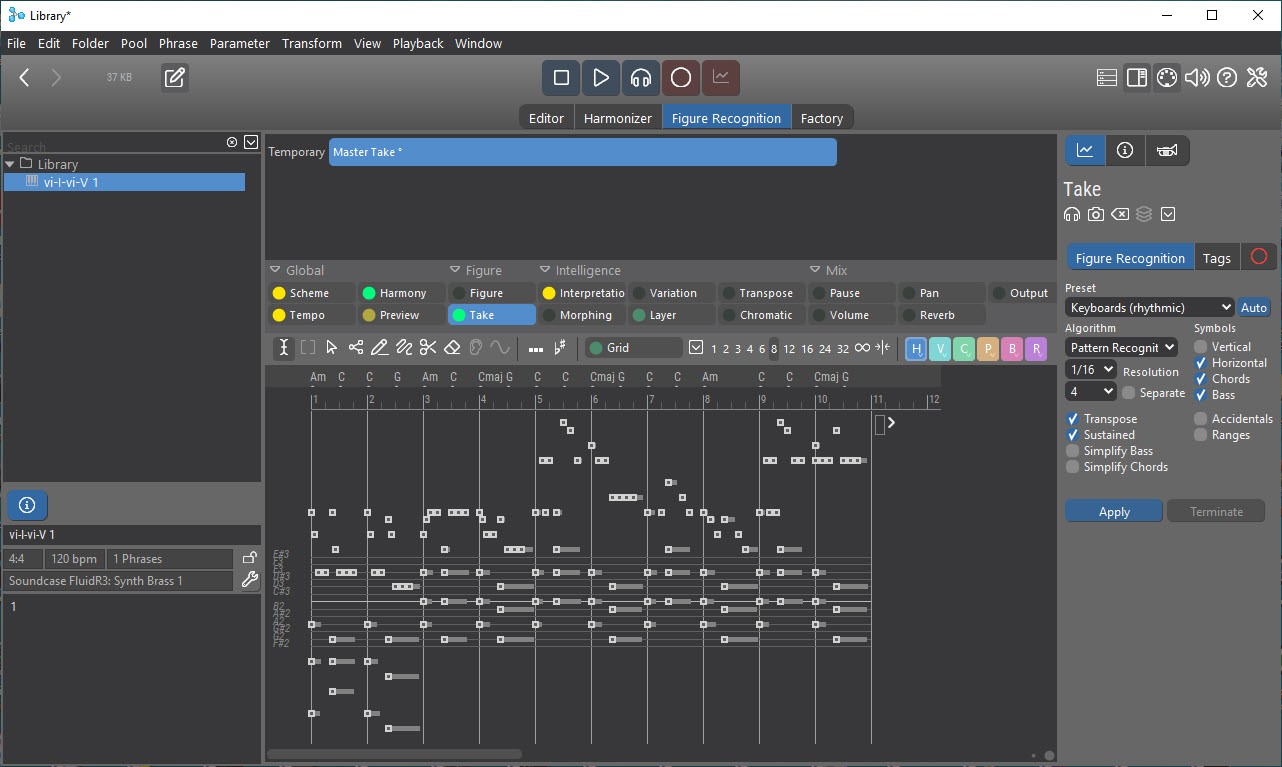
There are 10m in the file, and my intent is to create 5 figures, 2m long each.
So, I look to the split operations:
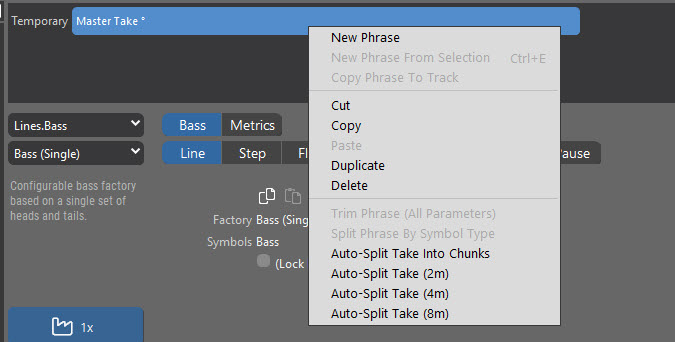
Looks like it will be a piece of cake.
But all of those Auto-Split options do absolutely nothing when I invoke them.
I think perhaps I'm misunderstanding something fundamental here.
Can anyone guide me about why I see no action from Auto-split, and what I should be doing instead to reach my goal of five 2m figures from the file?
Thanks!

Fri, 2023-12-15 - 22:36 Permalink
Hi, when a midifile is imported in the external library and divided into pieces, it is based on an algorithm that takes into account the musical context.
You can always use CTRL + E (extraction) in Windows and the span tool to make a selection from the imported phrases.
The "harvested" phrase is also placed in the library.
You can also import a midifile for example statically (shown in the arrangement window) and make selections and let the figure recognition loose on it to create a library of phrases.

Sat, 2023-12-16 - 11:19 Permalink
Yes, the naming of these split functions can be misleading. The prefix "Auto" hints at assessments going on behind the scenes, meaning they are not splitting a phrase verbatim into equal sized spans.
At the top level are "chunks": separate spans of activity in a long track. If a phrase is playing non-stop from start to finish, there is only a single chunk (nothing to split). This uses an adaptive algorithm and works really well to prepare long tracks for manual extraction.
Each chunk, if long enough, may be auto-split into smaller phrases with a preferred length, if there are distinguishable patterns that make good reusable phrases (which is the primary goal of import). This auto-detection of "phrase worthy-ness" is ridiculously complex and requires Deep Learning AI that is not yet ready for publication (e.g. phrases may partially overlap, there are pick-up melodies, etc). Doing this right is a whole field of research in its own. For the time being this uses a more simple algorithm.
And that algorithm seems to have come to the conclusion that your phrase does not suggest clearly discernable reusable phrases (probably because it's playing non-stop with similar density from start to finish).
I understand what you want is verbatim slicing no matter the content. That's on the wish list already.