
Posted
Hi,
As a test, I'm importing a simple MIDI file, which in this case is two musical phrases with a measure in-between.
After import, here is the Master Take:
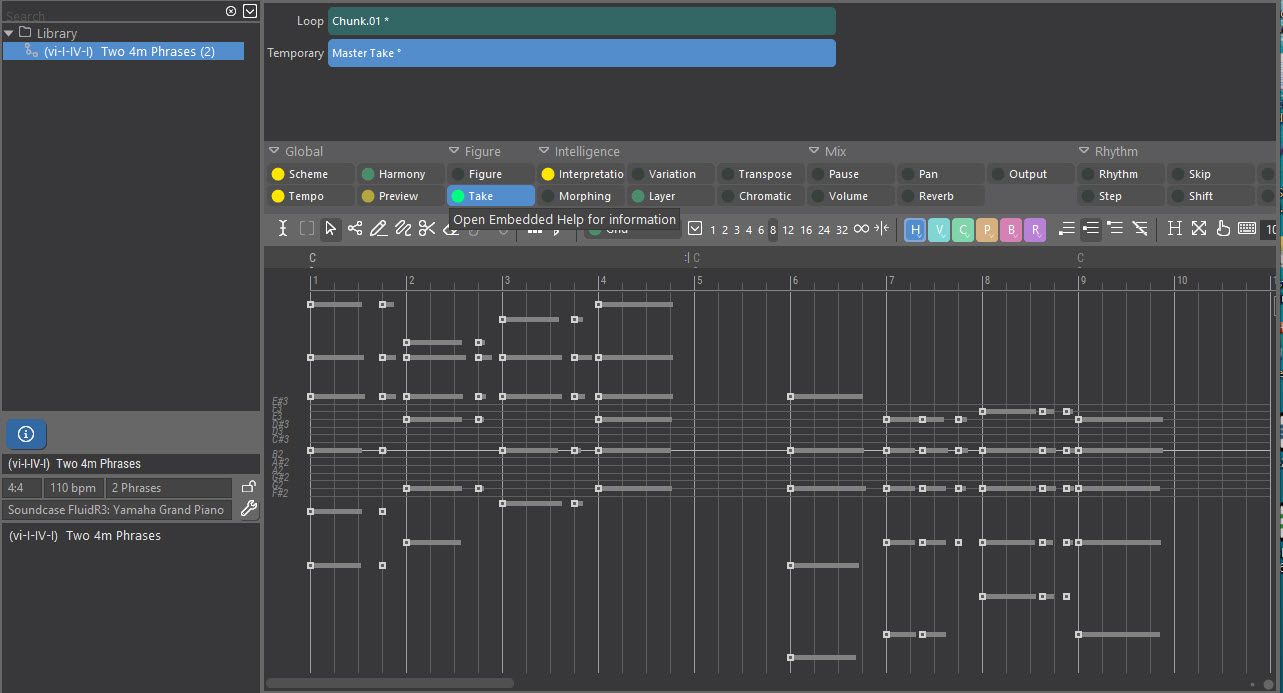
This shows what's in the file, just as a DAW would show it and as I've described it.
After the analysis, here is 'Chunk 01':
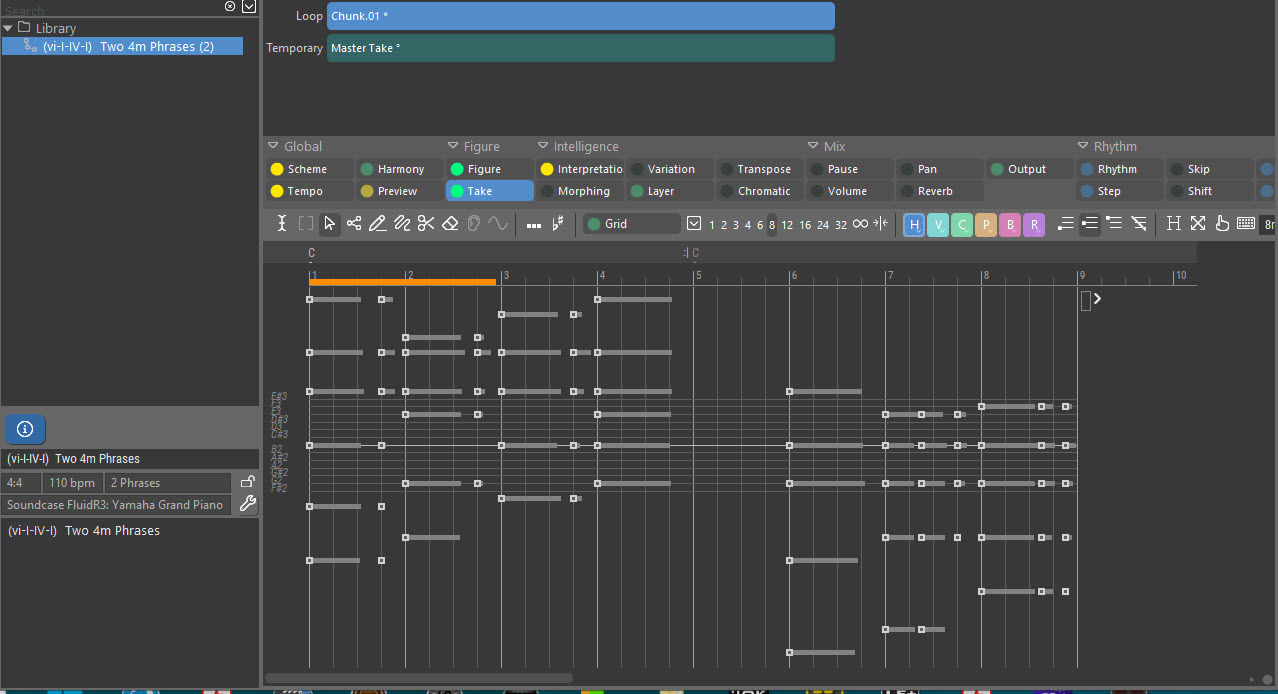
FWIW, this makes no sense to me, and I'd call it a bug in the chunking algorithm (which of course will affect everything done after).
The "correct" answer would be two chunks, 4m each.
I realize the analysis is meant in general for much more complex cases, and perhaps it works decently for those.
But it is hard to have confidence that is so when something as simple as the basic chunking, which is always the very first step in the analysis is demonstrably non-nonsensical (if I may put it that way!).
Is the AI hallucinating? <g>
MIDI file attached.

Mon, 2023-12-18 - 19:23 Permalink
A whole note rest is not enough to separate two chunks at the top level.
It is enough to separate them with Auto-Split. That gives you 3 phrases, with the the chord at 6m a short separate phrase. That's debatable. Probably a result of the 1m gap that shifts everything to the right, leading to odd measures.
What looks obvious to your eyes is actually not trivial. Synfire assumes an imported track contains music as it is performed. So the gap is not recognized as am artificial separator, but as part of the performance. And as such the chord at 6m indeed stands somewhat isolated (if you assume a scheme with an even number of measures per row).
Guessing the intentions of the user (what the phrases are supposed to be used for), the style (typical gaps, phrasings) and the "format" (if there is a deliberate separation of phrases within a track) is beyond the current capabilities of the algorithm. Even if it had 90% accuracy, you'd still get 1 bad track out of 10 that will mess up your library.
That said, I believe it is possible to make batch import more convenient. The proposed strict splitting mode will already help. Import without manual review is an impossibility though. There's just too much ambiguity involved.
Mon, 2023-12-18 - 22:34 Permalink
Interesting, thanks for your comments.
Perhaps at a future point there could be an Advanced Guidance (AG) page or dialog, not necessarily commonly accessed by a casual user, the purpose of which is to allow certain specific instructions to be given to the analyzer by the user to "solve" cases where there are known specifics that the user wants to guide the process.
For example:
Always create new chunk after silence of this length:
Never create chunks shorter than this length:
Etc.
Each such guiding rule would need an on/off switch and take 0 or more parameters to be used if On.
The developer would have to code in such items into the AG page, and could do so over time depending on user feedback from real usage in the field as various goals are attempted, and in light of what is technically possible or not in term of algorithm guidance.
Mon, 2023-12-18 - 22:37 Permalink
After writing the above, it occurs to me that that notion is not really greatly different, from the already existing Figure Recognition Presets.
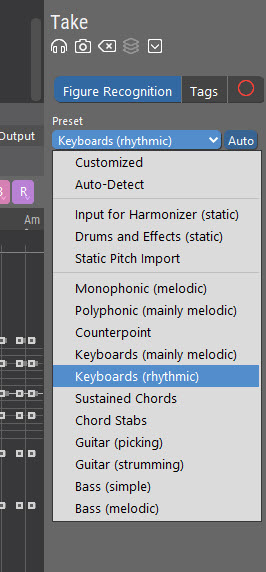
Maybe we just need some more of those to cover special cases such as the one discussed here.
Or maybe all those presets needs to be able to take certain forms of guidance.
Or maybe using both approaches would maximize the solution space, even while accepting that "perfect telepathy" <g> is unattainable.
Tue, 2023-12-19 - 08:27 Permalink
Running unattended mass imports feels great. However, imagine you imported 10k MIDI files automatically and ended up with 20 libraries. You'd need to sift through them all anyway, phrase by phrase, weed out the crap, remove redundancy, delete useless stuff, fix recognition issues, etc. IMO it's more effective to do that right up front, with each file, and only keep the stuff you want from the start.
Training AI models is cheap, if you have the labelled data. However, this is a special purpose for which no such data exists. Labelling is incredibly expensive (outsourced, crowdsourced). Imagine several thousand people sifting through 500k MIDI files, one by one. They need to be instructed, there needs to be oversight, quality assurance, etc. It costs millions.
For the preparation of imported files, classic solutions have enough potential to be good enough. It's not rocket science. I agree there is still plenty room for improvements.
Tue, 2023-12-19 - 12:38 Permalink
Running unattended mass imports feels great. However, imagine you imported 10k MIDI files automatically and ended up with 20 libraries. You'd need to sift through them all anyway, phrase by phrase, weed out the crap, remove redundancy, delete useless stuff, fix recognition issues, etc.
That's assuming that the MIDI files in question are not already "pre-vetted" musically as to chunks and phrasing.
Any musician could sit down and generate a MIDI file(s) which is a set of 4m musical chunks, as such, by playing - keeping only those which he/she accepts as decent. Musicians of the world could also do this collectively.
Indeed, such libraries of "MIDI loops" have long been available. In this case, the overriding concern when bringing that material into the Synfire environment is simply not to mess it up!
As has been stated, the current Synfire algos are primarily intended to tease phrases out of a long stream of continuous performance. Super, we need that!
We also need straightforward "as-is" ingestion of fragments that have already been defined as to their extent and validity.
Another important part of that need arises from modern MIDI "nugget" generation programs.
Programs like Captain plugins, Pilot plugins, Instacomposer, etc. can generate a practically unlimited number of short phrases of MIDI with ease. The user can then apply their own aesthetic sensibility as to which ones to keep or discard (incl. the possibility of keeping them all, if that is the choice made). After that, if the user is a Synfire user, the goal most certainly would be simple, accurate ingestion into Synfire libraries as the hopefully trivial prelude to getting on with the compositional process that Synfire's implementation of music prototyping allows.
So, in summary, MIDI file source material is born in at least 3 ways, representing -
a) complex continuous human performance
b) simple, segmented human performance
c) simple, segmented AI performance
I don't think there is any question that it is to the benefit of Synfire users if all 3 of these cases are well-accommodated.
How, exactly, to do that is certainly a design question/challenge!

Tue, 2023-12-19 - 14:57 Permalink
As has been stated, the current Synfire algos are primarily intended to tease phrases out of a long stream of continuous performance. Super, we need that!
You can also import midifiles as are static and manually "harvest" phrases from them.
In the arrangement screen import a midifile (maybe more than one at a time ?)
Don't know if at makes sense to import multiple midifiles at the same time, because if you have a midifile with 16 tracks then there are 16 instruments ( if the midifile supports the standard GM format).
The advantage of GM midifiles is that the instruments are automatically assigned in Synfire, so you can listen to them immediately I think.
You can quickly listen to a static midi instrument and pick out what sounds musical and do a further figure recognition for the final result.
Wonder what the possible not yet optimal automated phrase generation will come up with compared to the by ear selected phrases?
Good for a experiment ..